
Abstract
COVID-19 has created many complications in today’s world. It has negatively impacted the lives of many people and emphasized the need for a better health system everywhere. COVID-19 is a life-threatening disease, and a high proportion of people have lost their lives due to this pandemic. This situation enables us to dig deeper into mortality records and find meaningful patterns to save many lives in future. Based on the article from the New Indian Express (published on January 19, 2021), a whopping 82% of people who died of COVID-19 in Tamil Nadu had comorbidities, while 63 percent of people who died of the disease were above the age of 60, as per data from the Health Department. The data, part of a presentation shown to Union Health Minister Harsh Vardhan, show that of the 12,200 deaths till January 7, as many as 10,118 patients had comorbidities, and 7613 were aged above 60. A total of 3924 people (32%) were aged between 41 and 60. Compared to the 1st wave of COVID-19, the 2nd wave had a high mortality rate. Therefore, it is important to find meaningful insights from the mortality records of COVID-19 patients to know the most vulnerable population and to decide on comprehensive treatment strategies.
Similar content being viewed by others

1 Introduction
COVID-19 has had a major impact on the lives of many people and the economy. On August 30, 2020, India reported the world’s highest increase in COVID-19 cases in a single day. This analysis clearly exposes the severity and rapid spread of COVID-19 in our country compared to other countries. On July 10, 2020, in India, the pandemic had infected around 820,000 people, and the mortality rate was around 22,000. The rapid spread of this pandemic in our country definitely leads to harmful effects on the health systems of individuals, especially elderly people, immunosuppressed people, and people with certain comorbidity conditions like metabolic syndrome, cardiovascular disease, or respiratory disease. This, coupled with poverty, hunger, and migration problems, makes the situation further complex and increases the severity of COVID-19, thereby increasing the risk rate and decreasing the recovery rate. In Tamil Nadu, the reported cases were between 130,000 and 1829 deaths. Death cases accounted for 16% of total confirmed cases and 8.3% of total deaths in India. This shows that Tamil Nadu has negative implications for the enormous increase in mortality rates in our country. So, it is important to describe the major factors that are associated with COVID-19 deaths in Tamil Nadu by comparing the deaths among COVID patients with and without comorbidities and analyzing the most commonly occurring comorbidity and risk rate.
2 Literature survey
We have done an extensive literature survey and have captured research information on various perspectives of big data. The information that we gain through applying big data analytical techniques to healthcare data will bring about a modern change in healthcare. From the common cold to many life-threatening diseases, identifying the symptoms, treating the patients, and working on preventive steps is the normal flow. With common and subtle symptoms, it's an easier task, but when the symptoms and the set of comorbidity conditions get complicated, it becomes a drastic disaster for the healthcare industry to deal with. Thus, this requires an adaptable solution to get automated insights on a disease.
A study on who is dying from COVID-19 and when? An analysis of fatalities in Tamil Nadu, India, showed individual death summaries describing the clinical characteristics of deceased individuals (Daily Report on Public Health Measures Taken for COVID-19 Chennai: Directorate of Public Health and Preventive Medicine Health and Family Welfare Department 2021; Goh et al. 2020; Asirvatham et al. 2021). They estimate the time interval between the symptom onset date, the date of admission to the hospital, and death. They find these time parameters crucial for an increase in mortality rates. Age has a major role in determining the mortality rate, as the study shows people over 60 are more prone to death (Koya et al. 2021). We have done an extensive literature survey and have captured research information on various perspectives of big data. The information that we gain through applying big data analytical techniques to healthcare data will bring about a modern change in healthcare. From the common cold to many life-threatening diseases, identifying the symptoms, treating the patients, and working on preventive steps is the normal flow. With common and subtle symptoms, it's an easier task, but when the symptoms and the set of comorbidity conditions get complicated, it becomes a drastic disaster for the healthcare industry to deal with. Thus, this requires an adaptable solution to get automated insights on a disease. Death (Koya et al. 2021). The objective of the research was to prevent avoidable fatalities. The disease severity, increased admission rate in the intensive care units (ICU), and increased risk of mortality of COVID-19 are strongly associated with comorbidities such as diabetes, hypertension, obesity, cardiovascular disease, and respiratory system diseases and this study result confirms the previous findings.
Tawseef Ahmad Naqishbandi had done work on clinical big data predictive analytics to study the complicated set of comorbidities and unfavorable natural and social conditions among patients, which make medicinal services and healthcare extraordinarily difficult (Koya et al. 2021). According to him, clinical big data are the data generated by the human body in different blends. He gives an example, as one should be able to find out which patients who are at higher risk of cardiovascular disease are likely to be readmitted even after the implantation of a pacemaker or who will live longer than average. His model aims to use and sense the power of big data predictive analytics and has the capability to extract, transform, aggregate, accumulate, and analyze the exponentially growing data in terms of clinical variety to improve healthcare (Naqishbandi and Ayyanathan 2020).
3 Methods
This study uses COVID death data for a period of six months from the official Stop Corona website of Tamil Nadu. We perform exploratory data analysis on the deaths to get insights on the mortality trends in the state. For this paper, we used IBM Spark and Google Colab as the integrated development environment. As it executes the codes on the Google Cloud, it leverages hardware including GPUs and CPUs regardless of the power of our machine (World Health Organization WHO Coronavirus Disease (COVID-19) Dashboard 2020). We have used COVID death data for a period of six months from the official Stop Corona website of Tamil Nadu. We perform exploratory data analysis on the deaths to get insights on the mortality trends in the state (Guo et al. 2019; Dalan et al. 2020; Wrapp et al. 2020).
The data for the project are collected from the official stopcorona.tn.gov.in website. This official website of Tamil Nadu gives us accurate data about the comorbidity, clinical symptoms, RTPCR positivity date, issue days, and death date of a person. We have done data curation for the period of six months, from January to May. We have separated the dataset for people with and without comorbidities. This makes the analysis easier. We have data fields like death case no., age, gender, city, hospitalized city, RTPCR positivity date, date of admission in hospital, comorbidity conditions that the patient had, symptoms experienced, issue days, and the death date (Sze et al. 2021).
3.1 Basic statistical methods
Measuring the central tendency of different attributes shows that the mean age of patients who have died is 67. This describes the different indications of the central value chosen. It gives us insights on the average, min, max, standard deviation, and count of the central attributes that we have chosen. We see the death count with and without comorbidity and infer that those deaths with comorbidity rank the highest (Huang et al. 2020). We have done descriptive statistics on the age factor to see its impact on death.
3.2 F-test
The F-test is a statistical test that is used to test the equality of two population variances. This is to give the ratio of two variances. With age, the recovery rate becomes slower. Thus, the factor “age” plays a greater role in determining the recovery rate than the comorbidities that a person has.
3.3 Linear regression
For getting the value of a dependent variable when we have information on an explanatory variable, we use regression analysis. This is a statistical algorithm that is more commonly used to determine the strength and relationship between two variables. Issue days are the time interval that we have between the date of admission to a hospital and the death date of a patient. We must see a strong correlation between issue days and the age factor. Age influences this time interval a lot. With younger ages, the issue days are much longer. But the death here may be due to the critical comorbidity condition of the person (Leisman et al. 2020).
3.4 Logistic regression
Logistic regression is used to model the occurrence of certain events. We have identified the critical commodities that have influenced diabetes and hypertension. People with diabetes mellitus and systemic hypertension are more vulnerable to death than people with the rest of the other conditions. We have two possible discrete outcomes 0 and 1, based on whether a person has the specified comorbidity or not (Yang et al. 2020). f(x) = 1/1 + e^{− k (x−x_ {0})}.
This is the logistic function that is used to map the input variable to the dependent variable.
3.5 K-means
K-means clustering uses a similarity measure in the form of Euclidean distance. The basic idea of K-means is to consider a starting data point as a bigger cluster and then divide it into small groups based on the given user input. This algorithm iteratively looks for data points and then assigns them to their closest cluster. The silhouette coefficient, or score, is a parameter used to calculate the fineness of this clustering technique, and its value ranges between -1 and 1. For this COVID-19 data analysis, which uses squared Euclidean as a distance measure, the silhouette coefficient was between 0 and 1, which justifies clusters being apart from each other and clearly distinguished.
3.6 Random forest
The random forest algorithm is used for both classification and regression tasks and has an important feature that makes it very easy to measure the importance of each feature on prediction. In this COVID-19 data analysis, it is used to identify the correct combination of components. Certain preprocessing steps, like handling missing values and creating two new columns, diabetics and hypertension, were the most common comorbidities, so individual columns have been created and then labeled as 1 for having that comorbidity, otherwise 0. Then we labeled people 1 or 0 based on whether they have the comorbidity or do not have it. From Fig. S5, it is clear that analysis was performed on the factors diabetes and age. If a person has diabetes and is aged 20, they are labeled as 1, otherwise 0; this then proceeds with the splitting of train and test data from this COVID-19 data and then attains an accuracy of 0.918215. This is similar to hypertension, and it has an accuracy of 0.886029.
3.7 Gradient boost
The gradient boosting algorithm can be used for predicting not only continuous target variables but also categorical variables. When regression is performed, the cost function is used, which is the mean square error. In the case of classifiers, the cost function is log loss. Independent variables will be used for this algorithm. For this COVID-19 data analysis, first diabetes will be considered an independent variable, followed by hypertension. By considering diabetes and hypertension as independent variables, accuracy is 91.82 percent and 91.3 percent, respectively.
3.8 Fuzzy
Comorbidities are preexisting medical conditions that can increase the severity of COVID-19. Some common comorbidities include diabetes, hypertension, and obesity (Sinclair and Abdelhafiz 2020). To analyze the influence of comorbidities on COVID-19 severity, a dataset can be created that includes information on patients' comorbidities, COVID-19 symptoms, and outcomes. Fuzzy logic is a mathematical framework that allows for reasoning with imprecise or uncertain data. In the context of COVID-19 analysis, fuzzy logic can be used to model the uncertainty associated with comorbidities and other factors that may influence COVID-19 severity (Guan et al. 2020; Ayyanar, et al. 2021; Senthilnathan, et al. 2021; Shanmuganathan et al. 2023).
-
1.
Fuzzy logic modeling: Use fuzzy logic to model the uncertainty associated with the data. This may involve defining fuzzy sets for the input variables, creating fuzzy rules to relate the input variables to the output variable (COVID-19 severity), and using fuzzy inference to make predictions [15].
-
2.
Model training and validation: Split the data into training and validation sets, and use the training data to train the fuzzy logic model. Evaluate the model's performance on the validation set, and fine-tune the model as needed.
-
3.
Prediction: Use the trained fuzzy logic model to make predictions about the severity of COVID-19 for new patients based on their comorbidities and other relevant factors.
4 Implementation
In the implementation part, we all summarized the analysis and put it into a nutshell for predictive results. We used many algorithms to determine the relationship between comorbidity diseases and death rates. In addition to the algorithm, we had to use various big data techniques like PySpark to visualize the data with the factors called city, gender, age, etc., from the dataset. Figures 1, 2, 3, 4, 5 show the data preprocessing and statistical analysis of the COVID dataset.

Top 5 rows (displaying the top 5 from dataset)

Data type (data type of column)

Count (count of rows)

Preprocessing (preprocessing of null values)

Five-number summary (displaying the statistical derivation)
4.1 Data preprocessing and statistical analysis
From Figs. 1, 2, 3, 4, 5 we had done the basic steps to preprocess the dataset for predictive analysis and manipulate with the basic five summary to know more about the statistical domain.
4.2 Data visualization
With this interactive plot, Figs. 6 and 7 explain the death rate with respect to gender, and age vs. gender is demonstrated. We can see that the middle quartile of the male data (median) is 71, whereas the female data is 67. This means that 50% of male patients are younger than 71, and the other 50% are older than 71. Similarly, 50% of female patients are younger than 67, and the other 50% are older than 67. Upper quartile for male and female data: For male data, 75% of the age values fall below 78. For female data, 75% of the age values fall below 72. Lower quartile for male and female data: For male data, 25% of age values fall below 63. For female data, 25% of age values fall below 58. The range of age values from the lower to the upper quartile is called the interquartile range. From the plot, you can conclude that 50% of patients are aged 63 to 78 years (male). From the plot, you can conclude that 50% of patients are aged 58 to 72 years (female). If you take a look at whiskers, you’ll find the greatest value (excluding outliers), which is 90 for females and 95 for males. Our data contain only one outlier—a patient with an age of 103 for males and 94 for females. The lowest value is 21 for females and 30 for males, which is quite possible since the patients can be young adults. Figure 8 discusses the grouping of hospital types.

Death rate with respect to gender (death rate with respect to gender)

Age versus gender

Age versus hospital type (grouping of hospital type)
Generally, heat map is used to find the dependent variables in Fig. 9. It is one of the best ways to find the relationship between features. Figure 10 clearly visualizes death without comorbidities and with comorbidities. Correlation for tested cases and death cases is shown in Figs. 11 and 12.

Heat map (death case number, age, issue days)

Visualization (Comor vs. non-comor)

Correlation (tested date vs. died date)

Age (made descriptive statistics for the AGE column to analyze the recovery rate)
Figures 13, 14 explain F-test sampling. It shows that the recovery rate for aged people is very slow and difficult. We have created two new columns diabetics and hypertension. Then we had labeled 1 or 0 based on whether people have the comorbidity or do not have it, respectively. Figures 15, 16 show the complexity like sugar and BP involved in comorbidity people.

F-test (made the visualization of after F-test sampling and we came to inference that the greater than age numeric the recovery rate is very slow)

Pie chart (had displayed the top 7 cities in which most of the patients were admitted)

Count of DM and HTN (diabetics is the critical comorbidity which has caused higher deaths)

Random forest (comorbidity disease)
We have created two new columns diabetics and hypertension. Then we had labeled 1 or 0 based on whether people have the comorbidity or do not have it, respectively. Figures 17 and 18 explain the people with hypertension using random forest algorithm (Figs. 19, 20, 21, 22, 23, 24, 25, 26).

Diabetes (using random forest)

Hypertension (using random forest)

Linear regression (for age factor)

Feature selection (using K-means)

Silhouette scoring and standardization (using feature selection and standardization)

Silhouette scoring

Visualization graph (using silhouette score)
4.2.1 Accuracy

Random forest accuracy (for diabetes)

Random forest accuracy (for hypertension)

Gradient boost (for hypertension)
5 Conclusion and future work
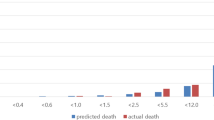
Based on the preliminary explorations of the dataset for the recent timeframe, it’s found that the median time interval from the time the patient tested positive until the death was 4 days. The median age of male patients who died is 71 years, and the interquartile range is between 63 and 78 years. Similarly, for the female patients who died, the median age value is 67 years, and the interquartile range is between 58 and 72 years. The mortality rate for male patients is 69.5%, whereas for female patients it is 30.5%. Adding on to our main theme of study regarding the impact of comorbidities, the COVID-19 death rate with comorbidities comprises 88% (approx.). The most commonly occurring comorbidities are type 2 diabetes mellitus (31%), systemic hypertension (26%), hypothyroidism (24%), and obesity (19%). With this preliminary approach, we extend our study to meet the objectives. This research study finds the category of people at high risk due to COVID-19 based on their historic medical conditions (i.e., the category of people who have a high likelihood of mortality due to COVID-19 attacks). We believe that these research findings can provide comprehensive insights into healthcare professionals and help them proactively plan to safeguard people's lives. This technique can also be applied to various diseases to identify vulnerable groups of patients with comorbidities.
The project “A Supervised Learning Approach for the influence of Comorbidities in the analysis of COVID-19 mortality in Tamil Nadu” has a significant potential for future scope. The project can be extended to cover other regions in India or even globally, to get a broader picture of the impact of comorbidities on COVID-19 mortality. The project can incorporate data from other sources, such as hospital records, vaccination data, and demographic data, to get a more comprehensive view of the factors affecting COVID-19 mortality. We can also include unsupervised learning techniques such as clustering, anomaly detection, and data visualization to uncover hidden patterns and relationships in the data. The project can be further developed to create predictive models that can forecast COVID-19 mortality based on comorbidities and other relevant factors. At last, we can plan collaborate with healthcare providers from government hospitals to collect more accurate and comprehensive data on comorbidities and other factors affecting COVID-19 mortality. This can help in the development of better prevention and treatment strategies for COVID-19.
Data availability
Not Applicable.
References
Asirvatham ES, Sarman CJ, Saravanamurthy SP, Mahalingam P, Maduraipandian S, Lakshmanan J (2021) Who is dying from COVID-19 and when? An Analysis of fatalities in Tamil Nadu, India. Clin Epidemiol Glob Health 9:275–279
Ayyanar J, Alqahtani SA et al (2021) Comorbidity and its impact on patients with COVID-19" in the diabetes & metabolic syndrome. Clin Res Rev J
Daily Report on Public Health Measures Taken for COVID-19 Chennai: Directorate of Public Health and Preventive Medicine Health and Family Welfare Department, Government of Tamil Nadu; 2021 from: https://stopcorona.tn.gov.in
Dalan R, Bornstein SR, El-Armouche A, Rodionov RN, Markov A, Wielockx B, Beuschlein F, Boehm BO (2020) The ACE-2 in COVID-19: Foe or friend? Horm Metab Res 52:257–263. https://doi.org/10.1055/a-1155-0501. -DOI-PMC-PubMed
Danat IM et al (2019) Impacts of overweight and obesity in older age on the risk of dementia: a systematic literature review and a meta-analysis. J Alzheimers Dis 70:s87–s99. https://doi.org/10.3233/JAD-180763. -DOI-PMC-PubMed
Goh KJ, Choong MC, Cheong EH, Kalimuddin S, Wen SD, Phua GC, Chan KS, Mohideen SH (2020) Rapid progression to acute respiratory distress syndrome: review of current understanding of critical illness from coronavirus disease 2019 (COVID-19) infection. Ann Acad Med Singap 49(3):108–118
Guan WJ et al (2020) Comorbidity and its impact on 1590 patients with COVID-19 in China: a nationwide analysis. Eur Respir J 55:2000547. https://doi.org/10.1183/13993003.00547-2020. -DOI-PMC-PubMed
Guo YR et al (2020) The origin, transmission and clinical therapies on coronavirus disease 2019 (COVID-19) outbreak–an update on the status. Mil Med Res 7(1):11
Huang C, Wang Y, Li X, Ren L, Zhao J, Hu Y, Zhang L, Fan G, Xu J, Gu X et al (2020) Clinical features of patients infected with 2019 novel coronavirus in Wuhan. China Lancet 395:497–506. https://doi.org/10.1016/S0140-6736(20)30183-5. -DOI-PMC-PubMed
Koya SF, Ebrahim SH, Bhat LD, Vijayan B, Khan S, Jose SD, Pilakkadavath Z, Rajeev P, Azariah JL (2021) COVID-19 and comorbidities: audit of 2,000 COVID-19 deaths in India. J Epidemiol Glob Health 11(2):230
Leisman DE, Deutschman CS, Legrand M (2020) Facing COVID-19 in the ICU: vascular dysfunction, thrombosis, and dysregulated inflammation. Intensive Care Med 46:1105–1108. https://doi.org/10.1007/s00134-020-06059-6. -DOI-PMC-PubMed
Naqishbandi TA, Ayyanathan N (2020) Clinical big data predictive analytics transforming healthcare: an integrated framework for promise towards value based healthcare. In: Advances in decision sciences, image processing, security and computer vision: international conference on emerging trends in engineering (ICETE), vol 2. Springer International Publishing, pp 545–561
Senthilnathan N, Lakshmanan DK et al (2021) A machine learning approach to identify risk factors associated with COVID-19 mortality in Tamil Nadu, India. Int J Infect Dis J
Shanmuganathan V, Suresh A (2023) LSTM-Markov based efficient anomaly detection algorithm for IoT environment. Appl Soft Comput 136:110054. https://doi.org/10.1016/j.asoc.2023.110054
Sinclair A, Abdelhafiz A (2020) Age, frailty and diabetes—triple jeopardy for vulnerability to COVID-19 infection. EClinicalMedicine 22:100343. https://doi.org/10.1016/j.eclinm.2020.100343
Sze S, Pan D et al (2021) Predictors of COVID-19 mortality in patients with comorbidities: a systematic review and meta-analysis. BMJ Open J
World Health Organization WHO Coronavirus Disease (COVID-19) Dashboard. Available online: https://covid19.who.int/?gclid=Cj0KCQjww_f2BRCARIsAP3zarHkU9pFKVYR5_E27j. Accessed 9 June 2020
Wrapp D et al (2020) Cryo-EM structure of the 2019-nCoV spike in the prefusion conformation. Science 367:1260–1263. https://doi.org/10.1126/science.abb2507. -DOI-PMC-PubMed
Yang J et al (2020) Prevalence of comorbidities and its effects in coronavirus disease 2019 patients: a systematic review and meta-analysis. Int J Infect Dis 94:91–95. https://doi.org/10.1016/j.ijid.2020.03.017. -DOI-PMC-PubMed
Funding
Funding is not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflit of interest
The authors declare that they have no conflict of interest. The manuscript was written through contributions of all authors. All authors have given approval to the final version of the manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Koteeswaran, S., Suganya, R., Surianarayanan, C. et al. A supervised learning approach for the influence of comorbidities in the analysis of COVID-19 mortality in Tamil Nadu. Soft Comput (2023). https://doi.org/10.1007/s00500-023-08590-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s00500-023-08590-2